
ML Engineering Needs A Taxonomy
Follow ML-Affairs On LinkedIn
Open the ML-Affairs page and follow it directly, or use the LinkedIn widget below.
If you spend enough time reading job descriptions in this space, a pattern starts to feel impossible to ignore.
Everyone says they want an ML Engineer.
And honestly, the ambiguity is getting tiring.
That reaction is not theoretical for me. I started much closer to data science: notebooks, experiments, signal, modelling. Then the work pulled me toward software engineering, data engineering, pipelines, deployment, observability, and production support, because useful ML does not stop at the point where a model looks promising.
Over time, that is how I grew into ML Engineering: not as a clean title switch, but as a set of responsibilities that kept appearing at the boundary between learning systems and production systems.
So my issue is not that titles need to be perfect. They never will be. Real work is messy, teams evolve, and people grow across boundaries. Some overlap is not only healthy; it is necessary.
But there is a difference between healthy overlap and lazy role design. The market keeps blurring the difference, then acts surprised when hiring becomes noisy and delivery becomes uneven.
Part of this is normal. Almost law-governed, in the sense that it was always going to happen once a young field started expanding quickly. First the work appears. Then the titles arrive. Then everyone tries to sound a bit more complete than they really are.
That is how you end up with profiles that drift from useful description into theatre:
- AI Strategist
- Data Whisperer
- Full-Stack ML Scientist
- MLOps Architect Evangelist
Some of that is harmless branding. Some of it is people trying to survive a confusing market. But the same exaggeration that helps people market themselves also makes the field harder to describe clearly.
And when companies copy that ambiguity into job descriptions, it stops being funny.
What they often seem to mean is:
- a data scientist who can productionise models
- a software engineer who understands modelling
- a data engineer who can own features and pipelines
- an ML platform engineer who understands infrastructure, MLOps, serving, observability, reproducibility, and the surrounding ecosystem of tools and practices
- if senior, then we are talking about someone who can also think about product, experimentation, and stakeholder communication
- and finally, someone who keeps up with a research landscape that has recently exploded in both depth and width
In other words, a unicorn.

This is not just a wording issue.
It is a taxonomy failure, and taxonomy is how teams coordinate work.
Role language decides what hiring loops test for, what teams staff for, what people own, and what they are judged against. Once that language becomes vague enough, the problem stops being semantic and becomes operational.
The field has become too wide for vague labels to carry this much responsibility.
When taxonomy fails, organisations do not just misname work. They mis-coordinate it.
The Ambiguity Problem
Terms like data scientist, applied data scientist, data engineer, software engineer, and ML Engineer are all used inconsistently.
Sometimes that is understandable. Real teams evolve. Smaller companies need broader people. Titles drift.
But the ambiguity is now large enough to create real problems:
- hiring managers ask for impossible overlap
- candidates do not know what success in the role actually means
- teams build fuzzy ownership boundaries
- delivery slows down because responsibilities are unclear
- people get judged against expectations nobody made explicit
When roles are unclear, ownership fragments. Work gets duplicated, responsibilities fall through gaps, and accountability becomes negotiable. The system does not just slow down; it becomes harder to reason about.
That is where this stops being semantics and starts becoming an organisational failure mode.
T-Shaped Is Good. Unlimited Width Is Not.
I am strongly in favour of people being T-shaped.
That matters. Breadth improves collaboration. It reduces blind spots. It helps teams understand each other’s constraints.
My own path depended on that kind of breadth. Moving from data science into software and data engineering was uncomfortable at times, but it made me a better engineer. It taught me why a beautiful model can still be useless if the features are unstable, the pipeline is fragile, the deployment path is unclear, or nobody can explain the production behaviour six months later.
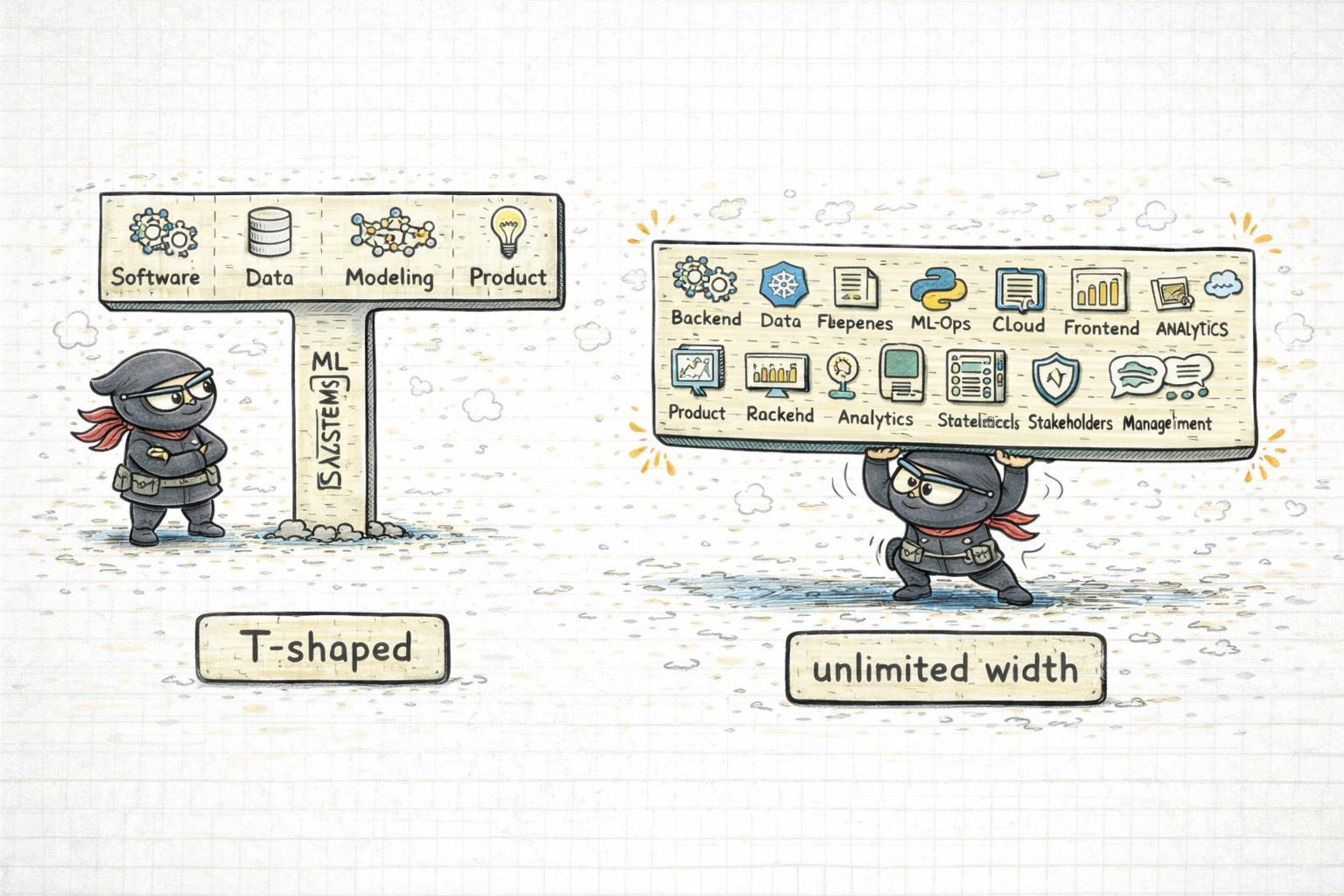
But there is a difference between healthy breadth and role collapse.
There is a point where “be cross-functional” turns into “please cover four disciplines badly enough that we can pretend one headcount is enough.”
That is not maturity.
That is under-specification disguised as ambition.
A Working Taxonomy
I do not think these roles need perfectly rigid borders, but I do think we need clearer centres of gravity.
1. Software engineers
Their centre of gravity is:
- application design
- interfaces and boundaries
- maintainability
- testing discipline
- deployment, reliability, and operational quality
They may or may not know much about modelling.
That is not the point of the role.
2. Data engineers
Their centre of gravity is:
- data movement
- storage and retrieval patterns
- pipeline reliability
- batch and streaming data infrastructure
- data quality and availability
They make sure the data side of the system can actually support the work being asked of it.
3. Data scientists
Their centre of gravity is:
- extracting signal from data
- experimentation
- hypothesis testing
- feature and model development
- evaluation and interpretation
They sit closest to learning from data and turning uncertainty into useful insight.
4. ML engineers
This is the ambiguous one, which is precisely why it needs more care.
To me, the ML Engineer owns the boundary between experimentation and production, where models, data, and systems must behave reliably under real-world constraints.
It is not “person who does some of all of the above.”
It is the role that cares about:
- turning model-driven logic into production systems
- managing the boundary between experimentation and serving
- making inference, features, deployment, monitoring, rollback, and reproducibility actually work together
- understanding enough of software, data, and modelling to make the whole thing operationally coherent
That is already a serious role.
It does not need to secretly absorb every adjacent discipline to be legitimate.
Where The Industry Gets It Wrong
The confusion starts when companies use ML Engineer as a placeholder for unfinished thinking.
Instead of deciding what the team is missing, they post a role that quietly asks for:
- modelling depth
- platform depth
- data pipeline ownership
- backend engineering
- experimentation design
- stakeholder fluency
- production support
Sometimes one person can cover a surprising amount of that.
In many cases, though, this is not confusion. It is a team design shortcut, trying to compress multiple roles into one headcount.
But building a role definition around the best-case outlier is not a sound organisational strategy.
Why This Matters In Practice
This ambiguity creates at least three practical problems.
1. It distorts hiring
If the role is unclear, the interview loop becomes unclear too.
You end up testing fragments of four disciplines and then pretending the aggregate signal means something precise.
2. It creates unfair expectations
People join thinking they were hired for one centre of gravity and then discover they are being evaluated against three others.
That is bad management, not professional growth.
3. It weakens team design
When roles are vague, interfaces become vague too.
And when interfaces are vague, teams stop designing good collaboration boundaries and start relying on heroic overlap. That creates ownership gaps, blame diffusion, duplicated work, burnout, and systems that degrade because nobody clearly owns end-to-end quality.
That does not scale well.
What We Need Instead
This is not really an argument about job titles.
It is an argument about how work is partitioned in complex systems: where the interfaces are, where ownership sits, and where accountability lands.
We need a clearer taxonomy and a more honest way of describing overlap.
Not rigid boxes.
But explicit definitions, shared language, and a better sense of where one role’s centre of gravity ends and another begins.
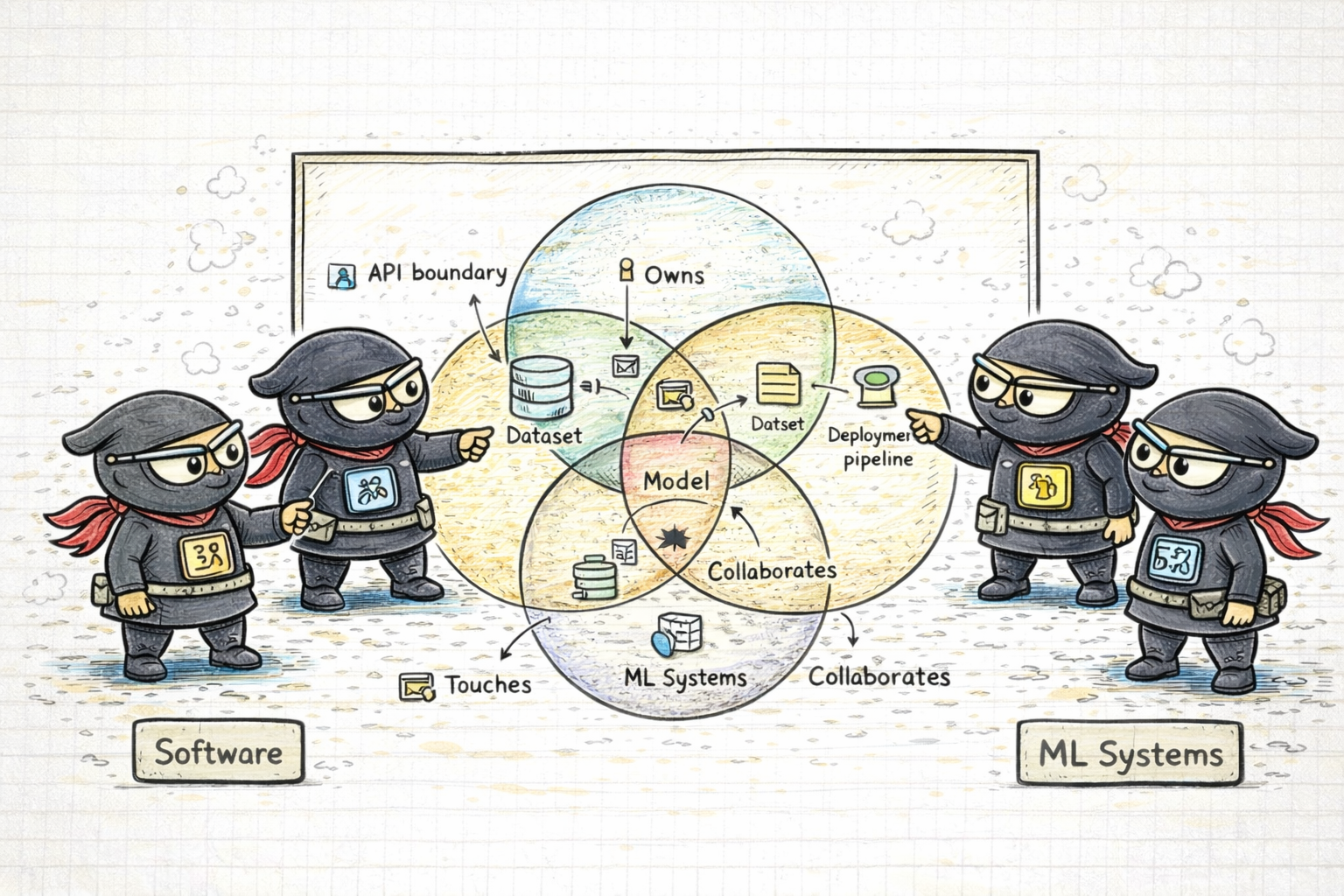
The interesting part is not eliminating overlap. The interesting part is naming it properly.
That is where tools like Venn diagrams, capability maps, and role definitions actually help. They force teams to say:
- what this role owns
- what it touches
- what it collaborates with
- what it is not expected to carry alone
That is healthier for hiring and much healthier for delivery.
The Real Takeaway
I do not think the industry needs fewer broad engineers.
I think it needs more honesty about what breadth costs.
T-shaped growth is real.
But asking one person to fully cover software engineering, data engineering, data science, and ML Engineering is usually not ambition. It is taxonomy failure.
Clearer role definitions are not admin. They are part of how complex work gets partitioned.
Once role definitions become vague enough, organisations stop designing teams and start relying on exceptional individuals. That might work occasionally. It does not scale.
A taxonomy is not bureaucracy. It is how the work gets divided clearly enough for systems, teams, and people to survive contact with production.