
Kafka Streams vs Flink Is The Wrong Question
Follow ML-Affairs On LinkedIn
Open the ML-Affairs page and follow it directly, or use the LinkedIn widget below.
I am not neutral about Flink.
I have spent years advocating for it, using it anywhere I could, organizing London meetups around it before COVID, and talking to anyone who would listen about why the dataflow model is such a good way to think. I still love that model. I love how naturally event-driven systems can align to a domain: a ship enters a port, this state changes, that downstream action happens next. Both Flink and Kafka Streams let you express stateful processes in a way that can stay close to business reality.
And that is exactly why this lesson was useful for me.
When I joined a later role, I found myself surrounded by repositories built with Kafka Streams. My first instinct was simple: replace them with Flink. Some of those repos were chaotic, under-loved, and far away from the kind of streaming architecture I like to build. I felt outside my waters. I wanted to modernize, refactor, migrate, clean the slate.
But over time, after giving those systems the attention they deserved, I learned something more valuable than another framework argument:
The useful question is not whether Flink is "better" than Kafka Streams.
The useful question is when your streaming problem stops being an application concern and becomes a platform concern.
That is still the line I care about most. But now I care about it with much more respect for both sides.
The Bias I Had To Correct
There is a recurring engineering mistake hiding in this topic: you inherit a system that feels old, untidy, or unfashionable, and you start reaching for the framework you know better.
I have had to relearn this lesson more than once in my career. It is almost embarrassing how often it comes back, which is probably proof of how important it is.
I originally wanted to replace those Kafka Streams solutions largely because I was more fluent in Flink. That fluency gave me clarity in one framework and discomfort in the other, and I briefly mistook that feeling for architecture.
That is a dangerous mistake.
Once I slowed down, cleaned up the code, made the domain model clearer, and brought more disciplined engineering practices to those codebases, I ended up with a much less dramatic conclusion:
if you give an existing streaming system enough love, enough structure, and enough respect for the underlying model, you can get very far without rewriting it.
That does not make Flink less good. It just makes engineering judgment less theatrical.
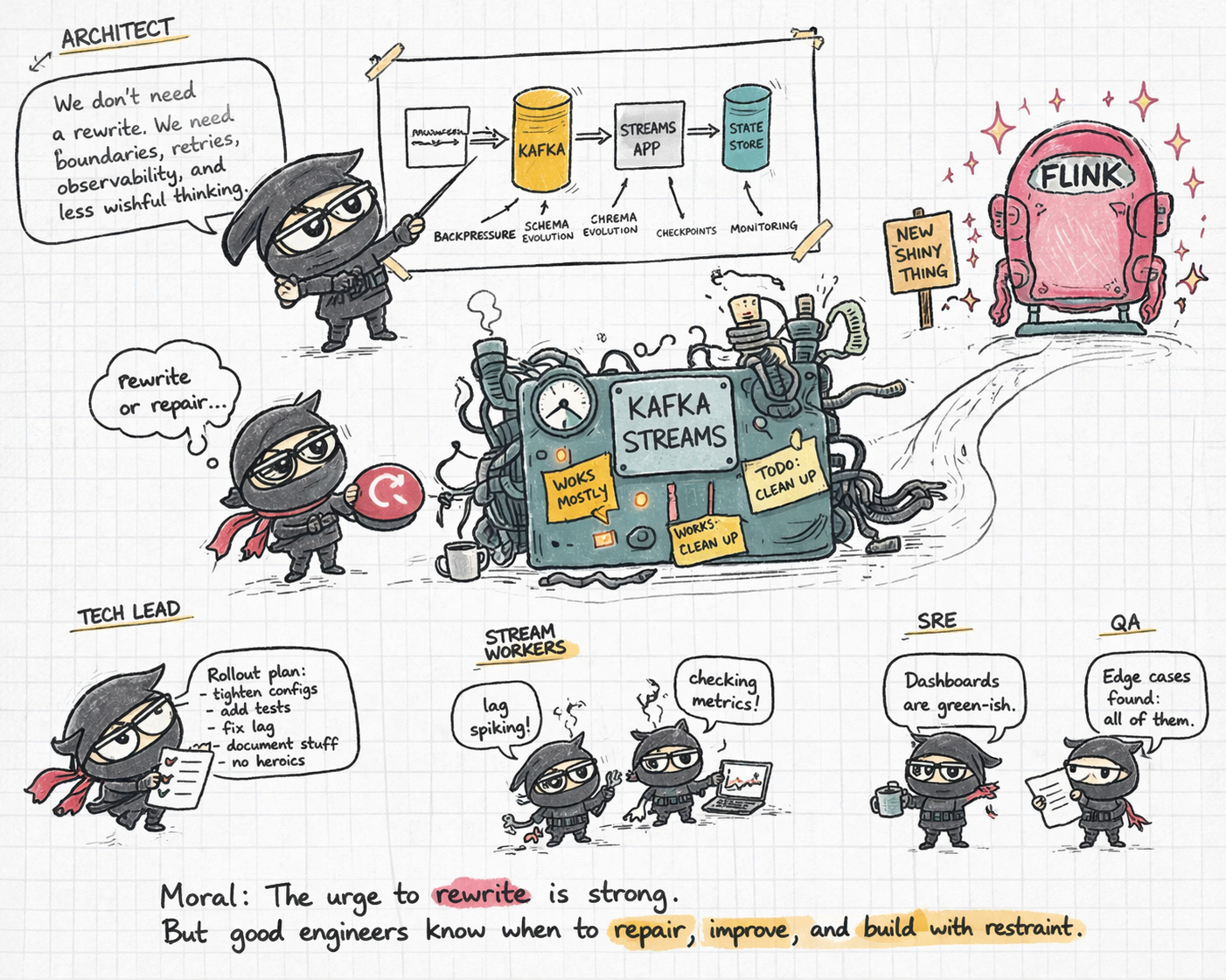
Framework preference is not architecture. My first instinct was to rewrite messy Kafka Streams systems into Flink. The better answer was to clean the model first, then decide whether the runtime was actually the problem.
What I Still Love About Flink
Let me be clear: I am still a very strong Flink advocate.
I still think the Flink dataflow model is one of the cleanest ways to reason about stateful stream processing. Operator boundaries are explicit. State feels local to the operator that owns it. Checkpointing, recovery, repartitioning, and event-time semantics feel like first-class runtime concepts instead of side effects of a library attached to a broker.
That is a big deal to me, because I care a lot about how easily a streaming system can be explained.
When a framework makes the flow of state and events easy to communicate, it usually also makes the system easier to maintain.
But none of that comes for free.
Flink asks you to pay an upfront complexity tax in operations, onboarding, debugging, and platform maturity. Misconfigured jobs are not charming. They are expensive. The model feels cleaner once you have paid that tax, not before.

This is why I still reach for Flink eagerly when the runtime itself needs to be a serious part of the design.
Where Kafka Streams Grew On Me
What changed for me was not that I stopped liking Flink. What changed is that I learned to appreciate where Kafka Streams is more enabling than I first allowed.
1. The State Model Is Different, Not Just Worse
One of the things that threw me off at first was the ergonomics of state in Kafka Streams.
Kafka Streams gives you state stores, changelog-backed recovery, and table-oriented patterns that can feel more globally available than Flink’s cleaner operator-local state style. The processor API is very explicit that processors interact with attached state stores, and those stores are fault-tolerant by default. In practice, the default persistent path is a local RocksDB store backed by a compacted changelog topic. On top of that, table abstractions and GlobalKTable-style patterns can make shared reference data or queryable state feel very convenient in the application model.
That convenience comes with real trade-offs:
- local RocksDB state is fast and useful, but fault tolerance still depends on changelogs
- restore times can still become painful at scale, especially when local state is lost and the store must rebuild from the changelog
- the relationship between topology code and materialized state can become messy in under-disciplined repos
- the convenience of reachable state can encourage poor habits if the model is not kept clear
But convenience is still convenience. There are use cases where having easier access to shared or queryable state is genuinely useful, and it would be dishonest to pretend otherwise.
My instinct, because of my Flink background, was to push Kafka Streams code toward a more operator-local way of thinking anyway: make state ownership clearer, keep logic close to the transform that really owns it, and avoid turning the topology into a stateful soup. That discipline improved those codebases a lot.
But that is exactly the point: bringing some Flink-style discipline into Kafka Streams made the code better. It did not prove that the whole system needed to become Flink.
2. Kafka-Native Integration Is A Real Strength
I am not even talking here about the obvious ecosystem point in a lazy way. Yes, Kafka Streams lives naturally inside the Kafka ecosystem. Yes, it works comfortably with keyed messages, schemas, topics, and the usual surrounding tooling. Yes, schema-registry-oriented flows often feel more straightforward there.
That matters. Not because Flink cannot do these things. It can. But because being native to the ecosystem reduces friction when the whole world around the application is already shaped like Kafka.
You should not dismiss that as a minor detail. It is part of the operating model.
Where Flink Still Pulls Away
This is where my original instincts still hold up.
1. Scaling Stops At The Broker Boundary Much Earlier In Kafka Streams
The scaling constraint in Kafka Streams is tightly tied to partitions, tasks, and instances. That is not a bug. It is the design. It is also why the system stays so close to Kafka itself.
But it has consequences.
There comes a point where adding more application instances does not really solve the problem because the partitioning boundary is already telling you how far you can go cleanly. You can absolutely scale Kafka Streams, but the broker topology keeps exerting a much stronger influence on the application topology.
At that point, scaling stops being primarily demand-driven and starts becoming topology-constrained.
Flink, by contrast, is still constrained at the source when consuming from Kafka, but once records are inside the runtime it has far more freedom to repartition, redistribute work, and run operators at a different parallelism from the source. I would not call that infinite scaling. I would call it a materially more flexible runtime.
That difference becomes major once traffic spikes, repartition pressure, or uneven workloads start shaping your architecture.
2. Checkpointing And Recovery Are In A Different League
This is still one of the clearest differentiators for me.
Flink’s checkpointing model is part of the platform. Recovery is an explicit runtime capability, not just the consequence of rebuilding local state from changelogs. The barrier-based snapshotting model, savepoints, and state redistribution semantics are exactly the kind of thing that make Flink feel like an engine rather than a library.
In Kafka Streams, the picture is a little more nuanced than “it always has to read the whole changelog again.” If the local state store still exists, the runtime can replay from the previously checkpointed offset and catch up from there. If local state is gone, it has to rebuild from the changelog from the beginning of the retained data. That is meaningfully better than a naive full replay every time, and it is one of the reasons the RocksDB path works as well as it does in practice.
But the deeper point still holds: fault tolerance and task migration are still anchored in changelog restoration, and on large stateful applications that can become one of the dominant operational pain points. Retention choices matter. Restore time matters. Recovery becomes less predictable under failure. Operational patience starts turning into architecture.
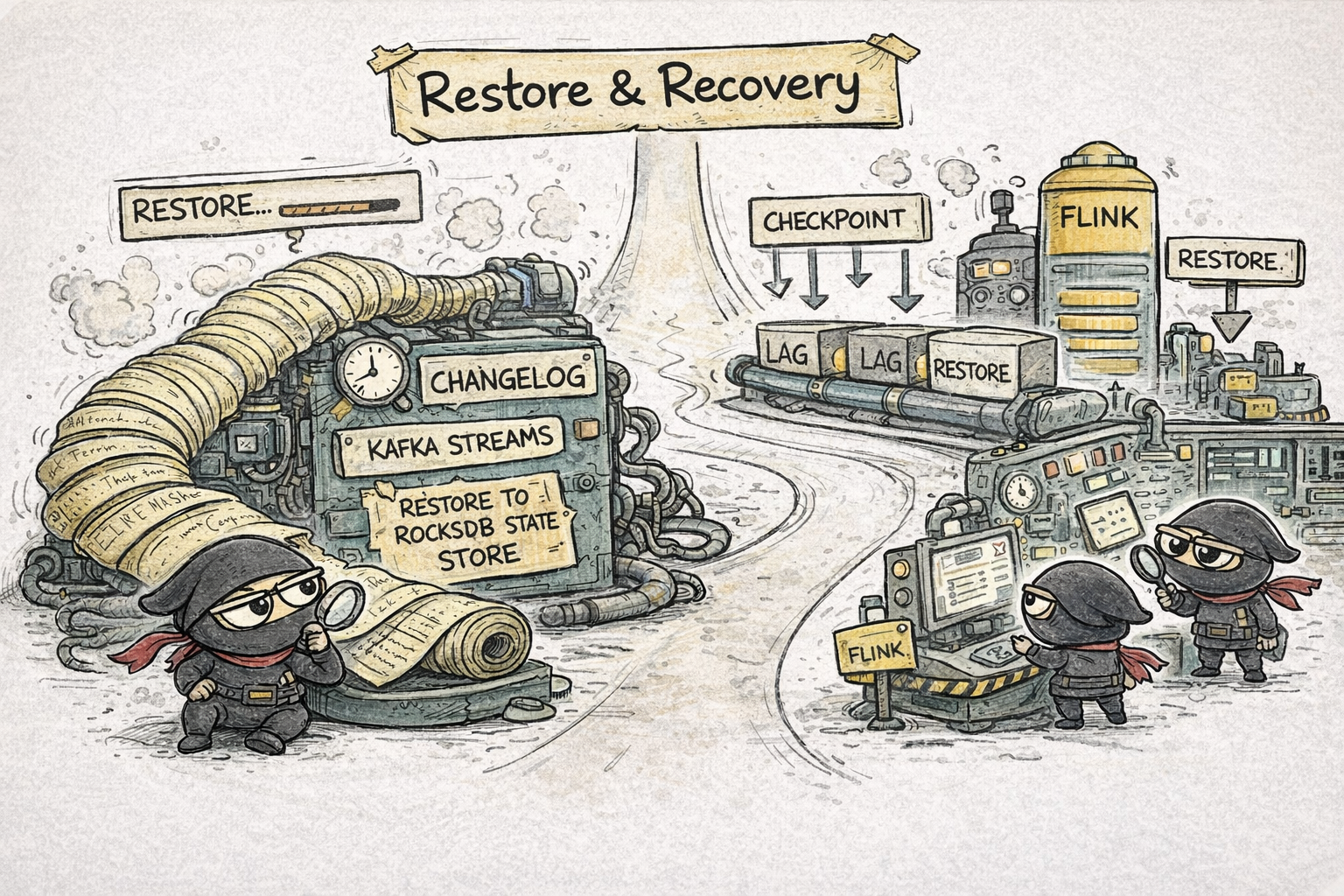
That is the point where Flink stops being a nice architectural preference and starts becoming a serious operational advantage.
The Real Trade-Off
So, here is the trade in one sentence:
Kafka Streams is a very good way to build Kafka-native streaming applications.
Flink is a very good way to operate stateful dataflows as a platform concern.
Those are not the same problem, even if the diagrams sometimes look similar.
And this is why I do not buy generic advice like “use Flink if you need scale” or “use Kafka Streams if you want simplicity.”
Both statements are misleading. They sound practical, but they hide the real failure modes, encourage cargo-cult architecture, and make comfort-driven rewrites sound more principled than they are.
The better rule is this:
If your system is still primarily an application that processes Kafka topics, Kafka Streams is often the right engineering choice.
If your system is becoming a stateful processing layer that needs explicit control over time, state, replay, recovery, and heterogeneous I/O, Flink starts to justify its existence very quickly.
The Harder Lesson
This is the part I most wanted to say personally.
I am still a huge Flink proponent. That has not changed.
What has changed is that I now trust myself less when my first reaction is “we should rewrite this in the framework I prefer.”
That reaction is often just comfort seeking.
Sometimes you really should migrate. Sometimes the runtime boundary is wrong, recovery is too painful, scaling is too constrained, and Flink is the more honest architecture.
But sometimes the better engineering decision is to love the existing system properly: clarify the model, clean the state boundaries, improve the abstractions, respect the domain flow, and stop assuming that old means wrong.
That was the lesson here for me.
If I had followed my first instinct blindly, I would have replaced some systems for the wrong reason.
What I Would Actually Do
If I were starting with a Kafka-centric JVM team, modest operational requirements, and clean Kafka-in/Kafka-out topologies, I would still be very happy with Kafka Streams.
I would move toward Flink once one or more of these became persistently true:
- stateful jobs became expensive to recover or rescale
- I needed a broader processing platform rather than a library
- event-time and replay behaviour started driving design choices
- the system stopped being comfortably Kafka-shaped
- operability and runtime visibility became a daily concern rather than an occasional debugging aid
That is the moment Flink stops being overkill and starts being the more honest architecture.
And that brings me back to where I started.
I still love Flink. I still think its model is easier to reason about once runtime concerns become serious. I still think it is the stronger platform when state, recovery, and rescaling dominate the design.
Many rewrites begin as comfort and only later get dressed up as architecture.
That is the part I understand better now, and it is probably the most useful thing this comparison taught me.