
From Model Validation To Pipeline Validation
Follow ML-Affairs On LinkedIn
Open the ML-Affairs page and follow it directly, or use the LinkedIn widget below.
Originally published on Medium on July 15, 2024. Lightly edited for the ML-Affairs archive.
Imagine making a decision today with the knowledge of tomorrow.
Sounds like an unfair advantage, right?
In machine learning, it is often a trap.
As an ML engineer at Vortexa, a lot of my work has lived in the space between abstract models and production tools that people can actually depend on. Over the years, my team and I have built and maintained data pipelines that feed downstream decisions in the energy domain. These systems do not just provide a snapshot of the market. They also provide signals that customers may use inside their own analysis, models, and decision workflows.
That creates a very natural retrospective question:
Had we incorporated Vortexa's predictions back in 2018, would the outcomes have been better?
That question is simple to ask and surprisingly easy to answer badly.
The Future Leakage Paradox
The usual temptation is to “travel back in time” by applying today’s model to historical scenarios.
That sounds reasonable until you notice the contradiction. If the model was trained using data that includes what happened after the period we are evaluating, then it is not really predicting the past. It is replaying the past with knowledge it should not have had.
Put differently:
A model should not be asked to predict an outcome from a past it has already learned.
That is not a small modelling detail. It changes the meaning of the whole evaluation. The model is no longer being tested as a prediction system. It is being tested as a memory system.
I started calling this the Future Leakage Paradox, or FLiP: a situation where future information seeps into a past prediction and makes the retrospective evaluation look more realistic than it really is.

Why This Matters In A Real Domain
Take vessel destination prediction as an example.
Suppose we want to evaluate how well a model would have predicted vessel destinations in 2018. The energy and shipping domains are volatile. Trade routes, demand patterns, sanctions, operational behaviour, and geopolitical constraints all change over time.
If a model trained after those changes is used to predict 2018, the retrospective result becomes misleading.

Consider COVID-19. The lockdowns in 2020 triggered a major drop in oil demand and changed shipping behaviour. If this information leaks into a model used to retrospectively evaluate 2018 predictions, the model can assign importance to patterns that were not available in the pre-pandemic world.
The same applies to the war in Ukraine and the subsequent sanctions on Russia. Those events affected vessel movements and trade flows. A model trained after those changes may encode relationships that did not exist, or were not knowable, in 2018.
That is the practical danger. Future leakage can make retrospective predictions look strong for the wrong reason.

The Shift: Validate The Pipeline
This is where I think the conversation should move from model validation to pipeline validation.
Taken too literally, that may sound provocative. Of course model performance matters. But as an engineer, I do not only care about whether one model trained once looks good. I care about whether the training pipeline can repeatedly produce good models under the constraints of time, data freshness, and production reality.
That distinction matters because retrospective prediction should not usually be done with one model.
If we have shipping data from 2016 onward and we want to predict 2018, one sensible approach is:
- train on 2016 and 2017
- predict 2018
- incorporate what actually happened in 2018
- train a new model for 2019
- repeat this process through later years
There are then two common strategies:
- an expanding window, where the training data grows over time
- a sliding window, where the model is trained on a fixed recent period
In both cases, the evaluation target has changed. We are no longer asking, “Is this one model good?” We are asking, “Can this pipeline keep producing reliable models as time moves forward?”

Model drift and new data will always push teams toward retraining. That means the training pipeline deserves the same level of care we already give to production ETL pipelines.
This is not just a nuance. It changes the engineering standard.
The objective is not to produce one impeccable model in isolation. The objective is to prove that the ML pipeline can generate a sequence of useful, traceable, reproducible models.

What Pipeline Validation Needs To Prove
Once multiple models become the norm, several engineering properties become central.
Idempotence And Determinism
Given a specific data snapshot and configuration, the pipeline should produce the same model, or at least an equivalent one, every time.
This matters because data scientists and engineers need to separate the impact of a code change from the noise of an unstable training process. If the same input can produce meaningfully different outputs without explanation, debugging becomes guesswork.
Consistency
The models produced across different windows should be held to a consistent standard.
One strong year is not enough. If the pipeline performs well only when the data is favourable, then the system is fragile. Pipeline validation should expose that fragility instead of hiding it inside aggregate metrics.
Temporal Stability
Performance over time matters.
If recent windows behave very differently from older windows, that may reveal changes in the domain, gaps in the feature set, data quality issues, or a pipeline that no longer captures the right signal.
Temporal instability is not always bad. Sometimes the world really has changed. But the pipeline should make that visible.
The Quest For Temporal Stability
Temporal stability is influenced by both the domain and the computational setup.
Nature Of Data Changes
In the energy domain, the structure of the data can evolve. Geopolitical events, operational shifts, and changes in trade flows can all affect the patterns a model needs to learn.
If the world is changing quickly, a sliding window may be more appropriate because it gives more weight to recent data. If there are longer-term cyclic patterns, an expanding window may provide a clearer view.
Business Objectives
If the goal is to understand long-term patterns, an expanding window may be the better fit. If the goal is to respond quickly to market changes, a sliding window may be more useful.
This is not only a data science choice. It is a product and business choice as well.
Computational Costs
As the available data grows, training on all historical data becomes more expensive.
If resources are constrained, a sliding window may be more practical because the dataset size stays bounded. That trade-off is not purely technical either. It affects how often the pipeline can run and how quickly the team can iterate.
The Model’s Ability To Forget
Some model classes can retain old patterns even when newer data suggests the world has moved on.
In those cases, a sliding window can help force the model to shed outdated patterns. An expanding window, by contrast, may overemphasise history that is no longer representative.
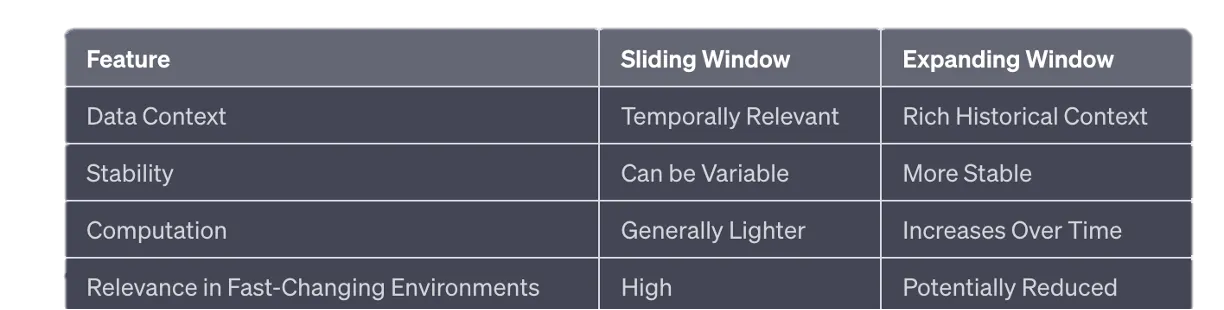
Sliding Vs Expanding Windows
There is no universal answer. The right choice depends on the problem, the data-generating process, and the cost of being wrong.
1. Sliding Window
A sliding window trains on a fixed-size recent period. For example, train on 2017-2018 to predict 2019, then slide forward and train on 2018-2019 to predict 2020.
The main advantage is temporal relevance. The model is always trained on recent data, which is useful in fast-changing environments.
The drawbacks are also real:
- it can miss longer-term patterns
- it can produce more variable results across windows
- it may discard useful historical context too aggressively
2. Expanding Window
An expanding window grows over time. For example, train on 2017-2018 to predict 2019, then train on 2017-2019 to predict 2020, and so on.
The main advantage is historical context. The model sees more of the past and may capture longer-term patterns.
The drawbacks are:
- computational cost grows over time
- old data may become less relevant
- the model may become slower to adapt to structural change
3. Hybrid Approaches
In some systems, a hybrid approach is more appropriate.
For example, an expanding window can be used up to a certain point, after which a sliding window keeps the training set bounded. Another option is a weighted expanding window, where recent data carries more weight but older data is not fully discarded.
Measuring Pipeline Effectiveness
Once the pipeline is the target, the metrics also need to widen.
Aggregate Metrics
Evaluate models across multiple periods and then look at aggregate metrics such as accuracy, precision, recall, F1 score, median performance, and variance.
The variance matters. A high median with unstable windows may still be operationally risky. A lower but more stable model may sometimes be more useful, depending on the product.
Adaptability
Data sources change. Feature sets evolve. Domain conditions shift.
A strong ML pipeline should adapt to these changes without silently degrading. That means versioning, traceability, and clear ownership of feature logic are not optional.
Data Leakage Detection
Data leakage is a silent killer in retrospective analysis.
Performance that looks too good to be true often is. Suspicious correlations, unrealistic jumps in performance, or features that depend on future outcomes should trigger investigation.
Some practical safeguards:
- Feature construction: features must not be calculated using future data.
- External data alignment: external datasets must obey the same temporal restrictions as the primary data.
- Shuffling care: random shuffling can destroy the meaning of time-series evaluation.
- Time-aware cross-validation: conventional cross-validation is usually the wrong tool for sequential data.
- Feature engineering per window: cleaning, normalisation, standardisation, and feature engineering should be re-executed for each data window.
The last point is easy to underestimate. If normalisation statistics are computed across the full dataset and then used inside older windows, future information has already leaked into the past.
Periodic Validation Applies To Live Models Too
The same principles apply to live models.
Retrospective validation makes the timeline problem obvious, but live models face the same pressure. Data changes, external conditions move, and the model’s assumptions age.
For neural networks, validation is often discussed around epochs. But the broader need for regular validation is not specific to neural networks. Any model that operates in a changing domain needs periodic checks that respect time.
Time-series cross-validation is useful because it tests performance across chronological splits. It helps expose overfitting, leakage, and temporal brittleness.
The goal is not only to keep a model fresh. The goal is to keep the validation story honest.
Efficiency And Traceability
Efficiency metrics are also part of the picture.
If training gets slower every time the data grows, the pipeline may become too expensive to run frequently enough. If traceability is weak, the team may not know which data, features, code, and hyperparameters produced a given model.
That lineage matters.
When multiple models are generated periodically, each one needs a clear record:
- data snapshot
- feature definitions
- training code version
- hyperparameters
- evaluation window
- output artefact
This is not bureaucracy. It is how teams make iteration explainable.
Without traceability, improvement becomes folklore. With traceability, each refinement builds on something the team can actually understand.
Last Words
Machine learning in the energy sector keeps evolving, as it does everywhere else. But the core lesson here is broader than one domain.
If the system needs to make claims about historical predictions, the validation process must respect history.
That means moving beyond a narrow question of whether one model performs well. The more useful question is whether the pipeline can repeatedly produce reliable, traceable, temporally honest models as the world changes around it.
In practice, that is the shift from model validation to pipeline validation.
And for production ML, that shift is not cosmetic. It is the difference between a model that looks good in retrospect and a system that could actually have made the prediction at the time.