
Harmonizing Avro and Python: A Dance of Data Classes
Christos Hadjinikolis, 07 November 2023
Reposting from the Vortexa medium blog
In the realm of data engineering, managing data types and schemas efficiently is of paramount importance. The crux of the matter? When data schemas are poorly managed, a myriad of issues arise, ranging from data incompatibility to runtime errors. What I am aiming for in this article is to introduce Apache Avro, a binary serialization format born from the Apache Hadoop project, through which I hope to highlight the significance of Avro schemas in data engineering. Finally, I will provide you with a hands-on guide on converting Avro files into Python data classes. By the end of this read, you’ll grasp the fundamentals of Avro schemas, understand the advantages of using them, and be equipped with a practical example of generating Python data classes from these schemas.

The Issue at Hand
Imagine the following scenario:
- Your application’s new update starts crashing for a specific set of users.
- Upon investigation, you discover the root cause: a mismatch between the expected data format and the actual data sent from the backend.
- Such mismatches can occur due to several reasons — maybe a field was renamed, or its data type got changed without proper communication to all stakeholders.
-
These are real-world problems arising from the lack of efficient schema management.
- So, how can Apache Avro and particularly avro-schemas help deal with these predicaments?
Avro… what now?
In the grand scheme of data engineering and big data, one might compare the efficient storage and transmission of data to the very lifeblood of the show. Now, if this show needed a backstage hero, it would be Apache Avro. This binary serialization format, conceived in the heart of the Apache Hadoop project, is swift, concise, and unparalleled in dealing with huge data loads. When the curtain rises for powerhouses like Data Lakes, Apache Kafka, and Apache Hadoop, it’s Avro that steals the limelight.
The Evolution of Data Serialization

Before diving into the tapestry of data’s history, let’s demystify a foundational concept here: serialization. At its core, serialization is the process of converting complex data structures or objects into a format that can be easily stored or transmitted and later reconstructed. Imagine packing for a trip; you organize and fold your clothes (data) into a suitcase (a serialized format) so that they fit neatly and can be effortlessly unpacked at your destination.
With that in mind, the story of data storage and transmission is a dynamic saga filled with innovation, challenges, and breakthroughs. Cast your mind back to the times of simple flat files–text files abiding to a specific structure. They were the humble beginning, like parchment scrolls in a digital era. But as data grew in complexity, our digital scrolls evolved into intricate relational databases, swift NoSQL solutions, and vast data lakes.
Now, imagine various systems, microservices, or extract-transform-load (ETL) pipelines, trying to communicate with one another by attempting to read unfamiliar data formats. It’s like trying to read a book when you don’t know the language it’s written in. To solve this, data had to be serialized–essentially translating complex data structures into a universally understood format. The early translators in this world were XML and JSON. Effective? Yes. Efficient? Not quite. They often felt like scribes painstakingly inking each letter, especially when handling vast amounts of data. The world needed a faster scribe; one that was both concise and precise.
Enter Avro. Inspired by the bustling highways of big data scenarios–from the lightning speed of Kafka to the vastness of Hadoop–Avro was born to ensure that data packets glided smoothly without unexpected stops. It became the guardian of data integrity and compatibility.
What’s in a POJO?
So, integrity is the keyword here, and in the context of this blog, we care about integrity breaches concerned with schema changes in a service that are not properly propagated to its consumers, rendering them unable to accommodate the new schema of the data they consume–like reading a book in a foreign language 😉.
The Dawn of the POJO Era
In the realm of programming, particularly within Java, a hero emerged named the Plain Old Java Object (POJO). This simple, unadorned object didn’t extend or implement any specific Java framework or class, allowing it to represent data without any preset behaviors or constraints. Imagine a Person POJO, detailing fields like name, age, and address without binding rules on how you should engage with these fields. Simple and elegant.
public class Person {
private String name;
private int age;
private String address;
// Default constructor
public Person() {
}
// Constructor with parameters
public Person(String name, int age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
// Getters and setters for each field
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
}
However, as data complexity increased and systems multiplied, ensuring that these straightforward representations, our POJOs, maintained their integrity when transmitted or stored across varying systems became a challenge. Manual serialization, translating each POJO for different systems, wasn’t just laborious — it was a minefield of potential errors.
Enter the need for an efficient and consistent serialization mechanism. One that could not only describe these POJOs but also seamlessly encode and decode them, ensuring data looked and felt the same everywhere.
Apache Avro & the Magic of Schemas
Amidst this backdrop, Apache Avro took centre stage. While the POJO painted the picture, Avro became the artist’s brush, allowing the artwork to be replicated without losing its original essence. Integral to Avro’s magic were its schemas. These files, with their unique .avsc extension, were a form of a blueprint, dictating the structure of an entity, data types, and nullable fields or default values. (see the Person.avsc as an example here).
{
"type": "record",
"name": "Person",
"namespace": "com.example",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
},
{
"name": "address",
"type": "string"
}
]
}
Pairing the intuitive design of POJOs with the precision of Avro schemas, developers had a formidable toolkit. Now, data could be managed, shuttled, and transformed without ever losing its core essence or structure. But what if these changes weren’t properly communicated amongst interacting systems?
Challenges in Schema Communication
Imagine two services: Service A (the Producer) that creates and sends data, and Service B (the Consumer) that receives and processes it. Service A updates its schema — perhaps it added a new field or modified an existing one. But if Service B is unaware of this change, it might end up expecting apples and receiving oranges.
- The Domino Effect: Let’s say Service A, our producer, changes a field from being a number to a string. Service B, expecting a number, might crash or perform incorrect operations when it encounters a string. In a real-world scenario, this could mean misinterpretation of important metrics, corrupted databases, or application failures.
- Versioning Nightmares: If every schema change requires updating the application logic in both the producer and consumer, this can quickly spiral into a versioning nightmare. How does one ensure that Service B is always compatible with Service A’s data, especially when they are updated at different intervals?
- Enter the Schema Registry: A centralized Schema Registry can be the saviour in this scenario. Instead of letting every service decide how to send or interpret data, the Schema Registry sets the standard.
- Registration & Validation: When Service A wishes to update its schema, it first registers the new schema with the registry. The registry validates this schema, ensuring backward compatibility with its previous versions.
- Schema Sharing: Service B, before processing any data, checks with the registry to get the most recent schema. This ensures it knows exactly how to interpret the data it receives.
- Library Generation: On successful registration, the producer can then trigger a script to create or update the corresponding POJO or Python data class. This automatically generated class can be used directly, ensuring that the code aligns with the latest schema.
Artifact Repository & Versioning
The generated data classes need a home. An Artifact Repository acts as this home. Whenever there’s a change, the updated class is given a new version and stored in this repository. Service B can then reference the specific version of the class it needs, ensuring data compatibility.
Producers, Consumers, and their Interaction: Once the schema changes are validated and registered, and the respective classes are updated, both the producer and consumer know exactly how to interact. They can reliably share data, knowing that both sides understand the data’s structure and meaning.
In essence, a centralised schema management system, paired with a robust registry and an efficient artifact repository, ensures that such data incompatibility issues are rendered not possible!
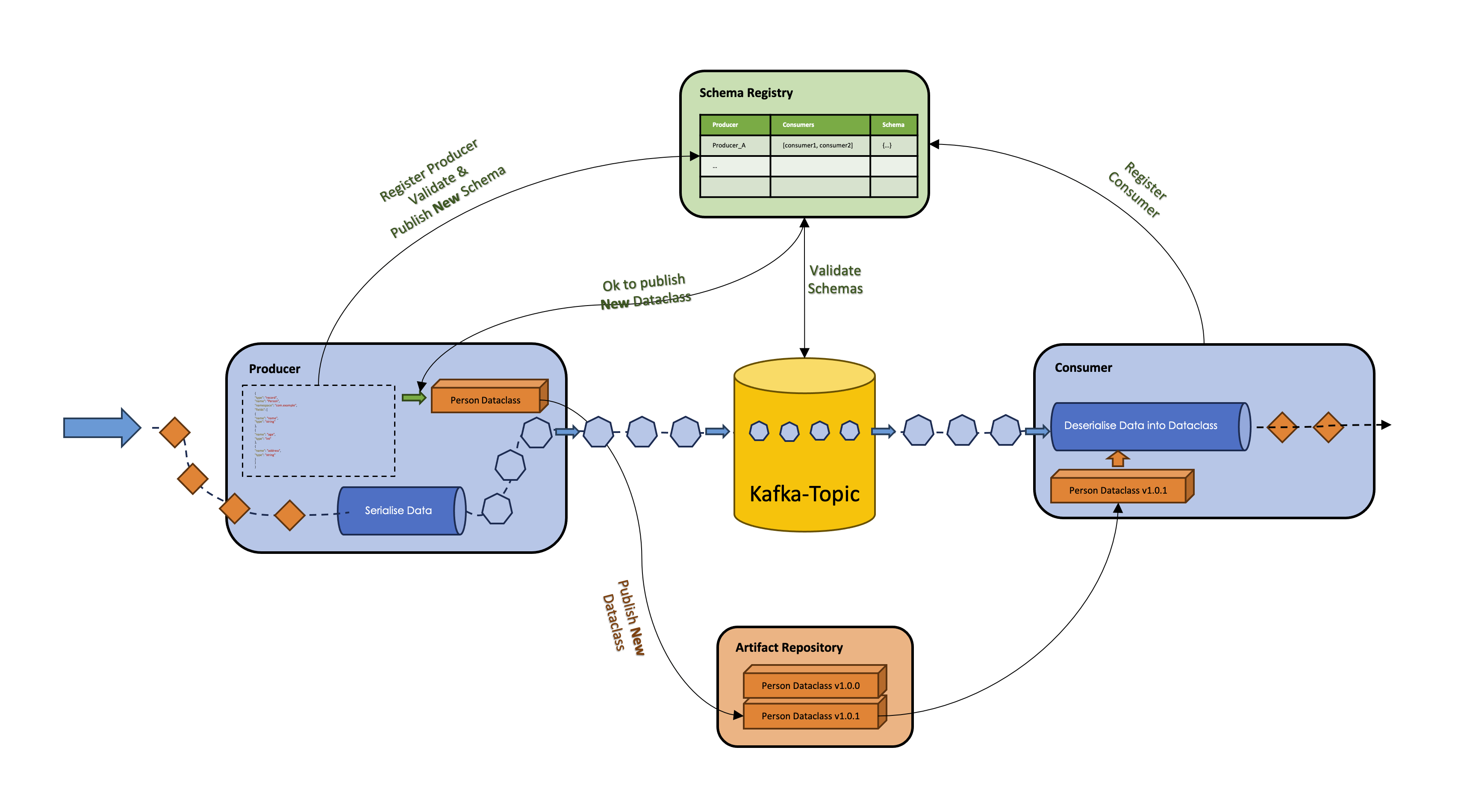
Generating Python Data Classes from *.avsc files
Avro, by its design and origin, has a strong affinity for the Java ecosystem. Apache Avro’s project comes with built-in tools and libraries tailored for Java, which makes generating POJOs straightforward. But when working with Python, things aren’t as easy.
Historically, it is worth noting that the introduction of data classes, which brought a feature similar to Java’s POJOs, came with Python 3.7. It, however, necessitated reliance on external libraries, such as dataclasses_avroschema, for schema-based generation. While these libraries are effective, their unofficial status can raise concerns about long-term reliability. Moreover, their utilization often depends on well-documented and clear examples, which might sometimes be ambiguous or lacking altogether. Furthermore, Python’s dynamic type system, though offering flexibility, poses challenges in maintaining data representation consistency when interfacing with Avro’s static schemas.
In this blog post, I hope to provide a clear example for data class-autogeneration, using an easy-to-understand script. So, let’s dive into an example.
Suppose, as we have already iterated, that we have the Person.avsc:
{
"type": "record",
"name": "Person",
"namespace": "com.example",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
},
{
"name": "address",
"type": "string"
}
]
}
Before providing the script, let’s discuss the sample project structure, which can help clarify why, later on, I state that the generated files must be read-only.
Sample Project Structure
Your project structure might look like this:
project/
│
├── resources/
│ └── schemas/
│ └── Person.avsc
├── src/
│ └── types/
│ └── Person.py
├── scripts/
│ └── generate_dataclasses.py
└── Makefile
resources/schemas/: This directory contains the Avro schema files (.avsc)src/types/: This directory will contain the generated Python data classes (.py).scripts/generate_dataclasses.py: This script generates the Python data classes from the Avro schemas-
Makefile: This file contains themakecommand to run the script. - Now, you can use the following Python script to generate a Python data class from this Avro schema:
import json
import os
import subprocess
from dataclasses_avroschema.model_generator.generator import ModelGenerator
def main():
print("Starting script...")
model_generator = ModelGenerator()
# Ensure the output directory exists
output_dir = "../src/types"
os.makedirs(output_dir, exist_ok=True)
# Scan the directory for .avsc files
for root, _, files in os.walk("../resources/schemas"):
for _file in files:
print(f"Generating DataClass for: {_file}")
if _file.endswith(".avsc"):
schema_file = os.path.join(root, _file)
output_file = os.path.join(output_dir, _file.replace(".avsc", ".py"))
# Load the schema
with open(schema_file) as sf:
schema = json.load(sf)
# Generate the python code for the schema
result = model_generator.render(schema=schema)
# Open the output file
with open(output_file, mode="w") as f:
# Write a comment at the top of the file
f.write("# This is an autogenerated python class\n\n")
# Write the imports to the output file
f.write("from dataclasses_avroschema import AvroModel\n")
f.write("import dataclasses\n\n")
# Remove the imports from the result because we have already written them to the output file
result = result.replace("from dataclasses_avroschema import AvroModel\n", "")
result = result.replace("import dataclasses\n", "")
# Write the generated python code to the output file
f.write(result)
# Format the output file using isort and black
subprocess.run(["isort", output_file])
subprocess.run(["black", output_file])
# Make the file read-only
os.chmod(output_file, 0o444)
print(f"Generated {output_file} from {schema_file}")
if __name__ == "__main__":
main()
This script will generate a Python file Person.py in the ../src/types directory with the following content:
# This is an autogenerated python class
from dataclasses_avroschema import AvroModel
import dataclasses
@dataclasses.dataclass
class Person(AvroModel):
name: str
age: int
address: str
class Meta:
namespace = "com.example"
Why Read-Only?
The generated Python files are made read-only to prevent accidental modifications. Since these files are autogenerated, any changes should be made in the Avro schema files, and then the Python files should be regenerated.
Conclusion
The integration of Avro files with Python data classes streamlines the complexities of data handling. It’s a union that empowers the data engineering toolkit, delivering precise type-checking, user-friendly code suggestions, rigorous validation, and crystal-clear readability. With the solid foundation provided by the schema registry, the integrity of your data remains uncompromised, no matter how intricate the data operations become. And while the magic lies in the technology and techniques discussed, the real art is in the consistent, reliable data flow it facilitates. As you delve deeper into the vast world of data, know that tools like these are pivotal in weaving the seamless narrative of your data story.
Stay tuned, as more insights await in follow-up discussions, where we’ll further dissect the intricacies of a comprehensive schema management ecosystem.
Remember to like my post and re-share it (if you really liked it)!
"Master your data flow with our latest guide on automated #Python data classes for #ApacheAvro schemas! A must-read for #DataEngineers. @DataCommunity #DataScience #SchemaRegistry"https://t.co/Jl1KUit4Ua
— Christos Hadjinikoli (@chatzinikolis) November 7, 2023
See you soon!
